Helix Is Intelligent

Monitor dashboards constantly
Traditional monitoring tools push teams into nonstop dashboard watching instead of clear action.

Ignore alerts due to fatigue
Too many false positives train teams to ignore alerts, increasing the chance of missing real incidents.

Wake up for non-critical issues
Helix answers the key question first: does this incident actually need action right now?
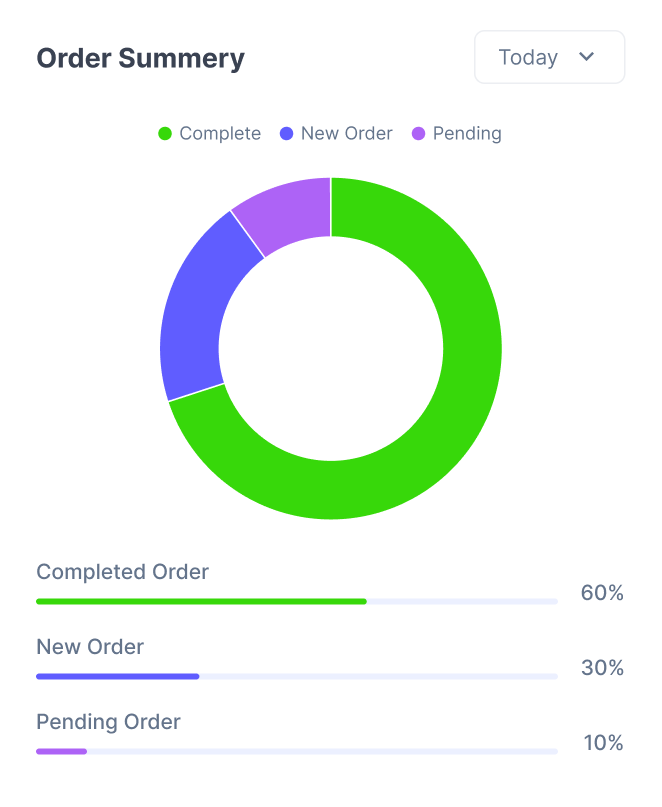


Critical Actions, Not Alert Floods
Detect downtime beyond acceptable limits and notify only when user impact is real.

Website Downtime
Critical ActionCatch payment and checkout failures quickly, with clear severity and next step.

Checkout Failure
Critical ActionTrack API latency against SLA thresholds so performance degradation is handled before escalation.

SLA Latency
Critical ActionMonitor CPU, memory, and infrastructure pressure to prevent outages before they spread.

Resource Exhaustion
Critical ActionIdentify systemic availability risks by correlating repeated incidents and related failures.

Availability Risk
Critical ActionReplace alert floods with focused incident intelligence so teams act faster with less fatigue.

Alert Deduplication
Noise ControlHelix adapts to teams running real production systems

SaaS Platforms
Ideal For
E-commerce Infrastructure
Ideal For
DevOps and SRE Teams
Ideal For
Cloud-native and Hybrid Setups
Ideal ForFrom Detection to Resolution - Automatically
When something breaks, teams check messages first. Helix sends incident summary, affected system, detection time, severity, and clear next step directly to WhatsApp.
Helix deduplicates repeated alerts, correlates related events, and only notifies teams when intervention is truly required.
Helix manages incident flow end-to-end: detect, notify the right people, wait for acknowledgment, escalate if needed, track resolution, and close when stable.
Critical Actions are business-impacting conditions you define, such as downtime, checkout failures, SLA latency breaches, and infrastructure availability risks.
Helix is designed for SaaS platforms, e-commerce systems, DevOps and SRE teams, CTOs, and engineering leaders operating mission-critical environments.
Helix is developed by Techelligence AI, combining deep AI agent expertise with infrastructure and DevOps experience for production-grade reliability.

Production-grade AI monitoring built for real-world operations
Stop Managing Alerts. Start Managing Outcomes.
Monitoring should demand attention only when it truly matters. Helix reduces alert fatigue, improves uptime, and gives teams clear ownership with faster incident response.
personGet StartedWith customizable dashboards tailored to your needs, collaborate effortlessly with your team and stay ahead with real-time updates.
© Helix is Proudly Owned by TechElligenceAI
Arpneet AI Technologies